[Oracle] 계층형 질의 Connect by 쉽게 이해해보기
계층형 질의 Connect by에 대해 이해한 바를 기록해두고자 한다.
(스스로 쉽게 이해하기에 중점을 둔 포스팅이라 작성된 내용은 정확한 용어 및 설명이 아닐 수 있음.)
1. 구성
SELECT column,...
, level, sys_connect_by_path(column, string), connect_by_isleaf
FROM ... [WHERE ...]
START WITH condition
CONNECT BY [NOCYCLE] condition ...
[ORDER SIBILINGS BY column, column...]1) 우선 기본적인 SELECT 문이 있어야한다. SELECT 문에서는 아래 값 등을 조회할 수 있다.
- level : 시작점으로부터 얼마나 멀어졌는지를 확인할 수 있다. [루트 = 1 / 루트의 하위 = 2 / ... 리프 = n]
- sys_connect_by_path(column, string) : 루트부터 현재 값까지의 경로를 지정한 string으로 연결하여 보여준다.
- connect_by_isleaf : 자식이 없는 값을 "리프 데이터"라고 하며, 리프 데이터 여부를 알려준다. [0:리프데이터가 아니다 / 1:리프데이터이다]
- connect_by_root : 현재 조회하고 있는 데이터의 루트 데이터를 조회한다.
2) START WITH condition
- condition에 만족하는 데이터부터 조회한다. 해당 데이터를 "루트 데이터"라고 부른다.
- 이 데이터의 레벨은 1이 된다.
3) CONNECT BY [NOCYCLE] condition
- condition에 만족하는 데이터를 자식 데이터로 지정하여 조회한다. 레벨이 1씩 증가한다.
- 다음으로 올 데이터가 이전에 지정했었던 데이터인 경우를 CYCLE이라고 하며, 이 때 런타임 오류가 발생한다.
- 해당 오류를 방지하기 위해 NOCYCLE을 지정하여, 이전에 지정했던 경우라면 지정하지 않는다.
- * PRIOR 을 이용해 지정할 컬럼을 정한다.
4) ORDER SIBILINGS BY column, ...
- 동일한 레벨의 데이터(=형제 노드)가 여러개인 경우, 해당 컬럼을 정렬할 우선순위를 정한다.
* PRIOR
구문은 CONNECT BY PRIOR A = B 과 같이 사용하고,
PRIOR 자식 = 부모 는 "현재 읽고 있는 데이터보다 하위데이터 중, 부모값이 현재 자식과 동일한 데이터"를 조회한다.
PRIOR 부모 = 자식 은 "현재 읽고 있는 데이터보다 상위데이터 중, 자식값이 현재 부모와 동일한 데이터"를 조회한다.
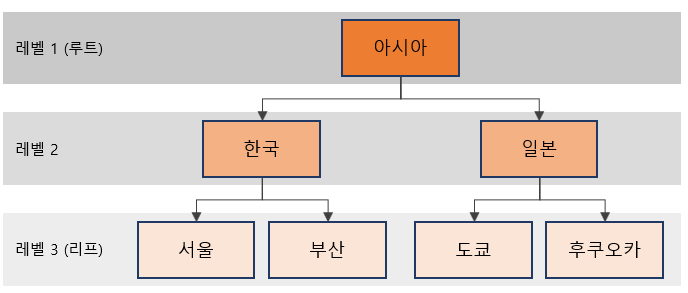
아래 이미지와 같이 <관계테이블A>라는 테이블에 A부터 F까지 전개하는 데이터가 있다고 해보자.

PRIOR 자식 = 부모는 다음과 같이 순방향 전개된다.
[1] A부터 조회 시작. 시작점인 A를 루트 데이터라고 부르며, 레벨은 1이다.
[2] A의 자식인 B,C 를 찾았다. 레벨은 1씩 증가하여 2가 된다.
[3] B의 자식인 검색하여 D,E 를 찾았다. 레벨은 3이다.
[4] D의 자식인 검색하여 F 를 찾았다. 레벨은 4이다.
=> C,E,F는 자식이 없으므로 가장 마지막 데이터, 즉 리프 데이터가 된다.
즉, 내 자식을 찾는 프로세스라고 생각하면 편하다!
PRIOR 부모 = 자식은 아래와 같이 역방향 전개된다. (아래의 결과가 출력되는 조건이라고 가정한다.)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ① - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[1] A부터 조회 시작. 루트 데이터이며, 레벨은 1이다. 더이상 부모가 없으므로 다음 데이터를 검색한다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ② - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[2] B부터 조회 시작. 루트 데이터이며, 레벨은 1이다.
[3] B의 부모인 A를 찾았다. 레벨은 2이다.
[4] A의 부모는 없기 때문에 A가 리프데이터가 된다. 다음 부모를 가지는 데이터를 조회한다.
[5] C부터 조회 시작. 루트 데이터이며, 레벨은 1이다.
[6] C의 부모인 A를 찾았다. 레벨은 2이다. B와 동일하게 해당 데이터가 리프 데이터가 된다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ③ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[7] D부터 조회 시작. 루트 데이터이며, 레벨은 1이다.
[8] D의 부모인 B를 찾았다. 레벨은 2이다. 2)~6) 순서를 동일하게 반복한다. 리프 데이터의 레벨은 3이다.
[9] E부터 조회 시작. 루트 데이터이며, 레벨은 1이다.
[10] E의 부모인 B를 찾았다. 마찬가지로 레벨이 3인 리프데이터가 나오며 종료된다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ④ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[11] F부터 조회 시작. 이하는 생략...
즉, 내 부모를 찾는 프로세스이다.
여기서 컬럼의 순서는 중요하지 않다. 어느 컬럼 앞에 PRIOR이 붙느냐가 중요하다.
즉, " CONNECT BY PRIOR 자식 = 부모" 와 " CONNECT BY 부모 = PRIOR 자식 " 는 동일한 결과를 나타낸다.
2. 예제
예제 테이블 구성은 다음과 같다.
create table city ( 코드 int not null, 상위코드 int, 이름 varchar(50) );
insert into city
(
select 100 코드, null 상위코드, '아시아' 이름 from dual
union
select 110 코드, 100 상위코드, '한국' 이름 from dual
union
select 111 코드, 110 상위코드, '서울' 이름 from dual
union
select 112 코드, 110 상위코드, '부산' 이름 from dual
union
select 120 코드, 100 상위코드, '일본' 이름 from dual
union
select 121 코드, 120 상위코드, '도쿄' 이름 from dual
union
select 122 코드, 120 상위코드, '후쿠오카' 이름 from dual
union
select 200 코드, null 상위코드, '유럽' 이름 from dual
union
select 210 코드, 200 상위코드, '영국' 이름 from dual
union
select 211 코드, 210 상위코드, '런던' 이름 from dual
union
select 220 코드, 200 상위코드, '프랑스' 이름 from dual
union
select 221 코드, 220 상위코드, '파리' 이름 from dual
union
select 300 코드, null 상위코드, '북아메리카' 이름 from dual
union
select 310 코드, 300 상위코드, '미국' 이름 from dual
union
select 311 코드, 310 상위코드, '뉴욕' 이름 from dual
union
select 312 코드, 310 상위코드, '시카고' 이름 from dual
union
select 320 코드, 300 상위코드, '캐나다' 이름 from dual
union
select 321 코드, 320 상위코드, '벤쿠버' 이름 from dual
union
select 322 코드, 320 상위코드, '토론토' 이름 from dual
);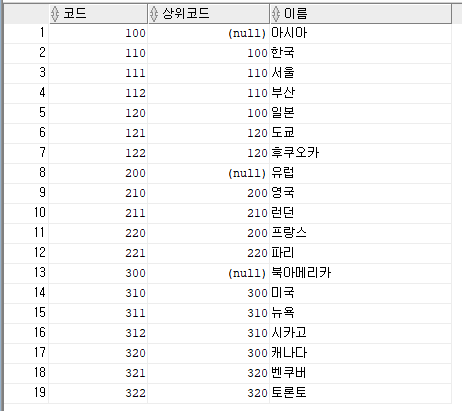

대륙, 나라, 도시가 저장된 테이블이다.
코드가 자식, 상위코드가 부모인 것을 알 수 있다.
이 테이블에서 "대륙 > 나라 > 도시 순으로 조회" 해보고 싶다면?
순방향 전개를 원하는 것이므로!
우선 최상위의 데이터인 대륙을 조회해야할 것이다.
즉, 대륙임을 알 수 있는 "상위코드가 없는 경우" 를 시작점으로 삼는다. ( = 루트데이터)
select * from city
START WITH 상위코드 is null;
그 다음 해당 대륙에 대한 나라를 조회해야한다.
우선 " CONNECT BY PRIOR 코드 = 상위코드 "를 사용하는 경우의 결과 값은 아래와 같다.
(이해가 쉽도록 레벨과 경로, 리프데이터 여부, 루트데이터를 같이 조회했다.)
select
코드,상위코드,이름
, level 레벨
, sys_connect_by_path(이름,' > ') 경로
, connect_by_isleaf 리프여부
, connect_by_root 이름 루트데이터
from city
start with 상위코드 is null --부모 지정
connect by prior 코드 = 상위코드; -- == "prior 자식 = 부모" == 순방향(부모→자식)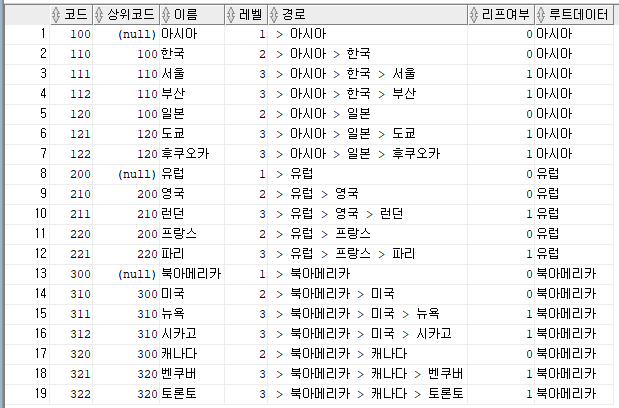
내용을 살펴보면,
[1] 상위코드가 null인 '아시아(100)'부터 조회 시작. 루트 데이터이며, 레벨 1이다.
[2] '아시아(100)'의 코드와 상위코드가 동일한 경우, 즉 자식인 '한국(110)'을 찾았다. 레벨은 2이다.
[3] '한국(110)'의 자식인 검색하여 '서울(111)', '부산(112)'을 찾았다. 레벨은 3이다.
[4] '서울(111)', '부산(112)'의 자식을 검색하지만, 더이상 데이터가 없다.
[5] '한국(110)'에 대한 자식을 모두 찾았으므로 [2]로 돌아가 '아시아(100)'의 자식인 '일본(120)'을, '일본(120)'의 자식인 '도쿄(121)','후쿠오카(122)'를 찾았다.
[6] '아시아(100)'에 대한 자식을 모두 찾았으므로 [1]로 돌아가 상위코드가 null인 '유럽(200)'부터 조회 시작.
... 반복된다.
" CONNECT BY 코드 = PRIOR 상위코드 " 로 바꾸면 결과는 완전히 바뀐다.
select
코드,상위코드,이름
, level 레벨
, sys_connect_by_path(이름,' > ') 경로
, connect_by_isleaf 리프여부
, connect_by_root 이름 루트데이터
from city
start with 상위코드 is null --부모 지정
connect by 코드 = prior 상위코드; -- == "자식 = prior 부모" == "prior 부모 = 자식" == 역방향(자식→부모)
[1] 상위코드가 null인 '아시아(100)'부터 조회 시작. 루트 데이터이며, 레벨 1이다.
[2] '아시아(100)'의 상위코드(null)와 코드가 동일한 경우, 즉 부모를 찾는다. 해당 데이터가 없으므로 다음 데이터를 검색한다.
[3] 상위코드가 null인 '유럽(200)'부터 조회 시작. 루트 데이터이며, 레벨 1이다.
[4] '유럽(200)'의 부모를 찾는다. 해당 데이터가 없으므로 다음 데이터를 검색한다.
[5] 상위코드가 null인 '북아메리카(300)'부터 조회 시작. 루트 데이터이며, 레벨 1이다.
[6] '북아메리카(300)'의 부모를 찾는다. 해당 데이터가 없으므로 다음 데이터를 검색한다.
[7] 더이상 데이터가 없으므로 전개를 종료한다.
결론적으로, 맨처음 조회하고자 했던 "대륙 > 나라 > 도시 순으로 조회"는 다음과 같이 where절을 추가하여 조회하면 된다.
select
코드,상위코드,이름
, level 레벨
, sys_connect_by_path(이름,' > ') 경로
, connect_by_isleaf 리프여부
, connect_by_root 이름 루트데이터
from city
where connect_by_isleaf = 1
start with 상위코드 is null
connect by prior 코드 = 상위코드;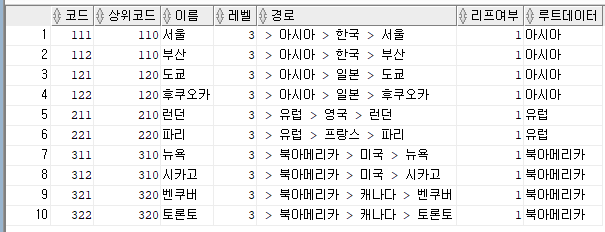
계층형 질의를 모두 완수한 뒤에, where절이 적용된다는 것을 알 수 있다.
시작점을 바꿔보면 어떨까?
"나라를 특정하여 나라 > 도시 순으로 조회"하고 싶은 경우에는 시작점을 해당 도시로 바꾸면 된다.
select
코드,상위코드,이름
, level 레벨
, sys_connect_by_path(이름,' > ') 경로
, connect_by_isleaf 리프여부
, connect_by_root 이름 루트데이터
from city
start with 코드 = '120'
connect by prior 코드 = 상위코드;
시작점을 '코드가 120인 경우' 지정한 결과이다.
[1] 코드가 120인 '일본(120)'부터 조회 시작. 루트 데이터이며, 레벨 1이다.
[2] '일본(120)'의 코드와 상위코드가 동일한 경우, 즉 자식인 '도쿄(121)', '후쿠오카(122)'을 찾았다. 레벨은 2이다.
[3] '도쿄(121)', '후쿠오카(122)'의 자식을 찾는다. 해당 데이터가 없으므로 다음 데이터를 검색한다.
[4] 더이상 데이터가 없으므로 전개를 종료한다.
물론 시작점이 더 상위의 값이라면 where절을 통해서도 원하는 값을 추출할 수 있다.
--시작점이 상이해도 동일한 결과를 만들 수 있다.
select
코드,상위코드,이름
, level 레벨
, sys_connect_by_path(이름,' > ') 경로
, connect_by_isleaf 리프여부
, connect_by_root 이름 루트데이터
from city
where 코드 = 120 or 상위코드 = 120
start with 상위코드 is null
connect by prior 코드 = 상위코드;
끝!
DB 자격증을 준비하다가 역방향이라는 개념이 헷갈려서 열심히 적어보았다.
부족한 설명이지만 누군가에게는 도움이 되었으면 해서 적어본다... ㅎㅎ;
댓글